用scrapy写爬虫(五)框架解析
本文共 408 字,大约阅读时间需要 1 分钟。
1 Scrapy框架
Scrapy是为爬取网站数据,提取结构性数据而编写的应用框架,可以应用在包括数据挖掘,信息处理或存储历史数据等方面。2 Scrapy框架图
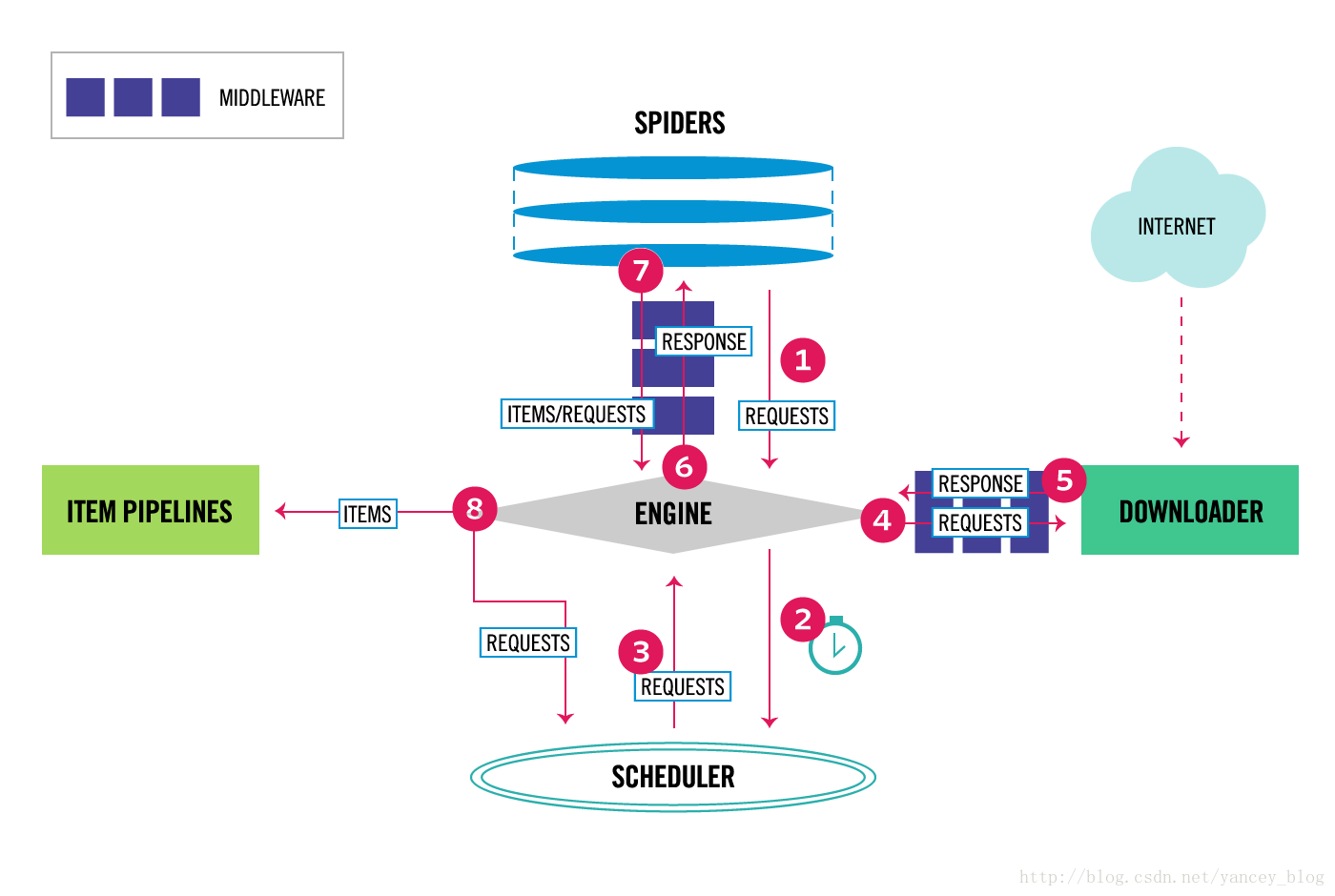
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎获得初始请求开始抓取。
2、爬虫引擎开始请求调度程序,并准备对下一次的请求进行抓取。 3、爬虫调度器返回下一个请求给爬虫引擎。 4、引擎请求发送到下载器,通过下载中间件下载网络数据。 5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎。 6、引擎将下载器的响应通过中间件返回给爬虫进行处理。 7、爬虫处理响应,并通过中间件返回处理后的items,以及新的请求给引擎。 8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器,调度器计划处理下一个请求抓取。 9、重复该过程(继续步骤1),直到爬取完所有的url请求。3 数据流图
绿色箭头代表数据流向
你可能感兴趣的文章
判断时间或者数字是否连续
查看>>
docker-daemon.json各配置详解
查看>>
Mac 下docker路径 /var/lib/docker不存在问题
查看>>
Docker(一)使用阿里云容器镜像服务
查看>>
Docker(二) 基础命令
查看>>
Docker(三) 构建镜像
查看>>
Spring 全家桶注解一览
查看>>
JDK1.8-Stream API使用
查看>>
cant connect to local MySQL server through socket /tmp/mysql.sock (2)
查看>>
vue中的状态管理 vuex store
查看>>
Maven之阿里云镜像仓库配置
查看>>
Maven:mirror和repository 区别
查看>>
微服务网关 Spring Cloud Gateway
查看>>
SpringCloud Feign的使用方式(一)
查看>>
SpringCloud Feign的使用方式(二)
查看>>
关于Vue-cli+ElementUI项目 打包时排除Vue和ElementUI
查看>>
Vue 路由懒加载根据根路由合并chunk块
查看>>
vue中 不更新视图 四种解决方法
查看>>
MySQL 查看执行计划
查看>>
OpenGL ES 3.0(四)图元、VBO、VAO
查看>>